How to train the ID3 Classifier to Perform Classification (SPMF documentation)
This example explains how to run the ID3 algorithm using the SPMF open-source data mining library.
What is ID3?
The ID3 algorithm is an algorithm for classification, proposed in the following paper:
Li, J. Han, and J. Pei, ID3: Accurate and efficient classification based on multiple class-association rules,in 2002 IEEE International Conference on DataMining(ICDM01), 2001, pp. 369-376
The ID3 algorithm is a classic data mining algorithm for classifying instances (a classifier). It is well-known and described in many artificial intelligence and data mining books.
The ID3 algorithm takes as input a dataset that consists of a set of records, described using attributes, assumed to be nominal attributes (strings). The goal of classification is to guess the missing value of an attribute called the target attribute based on the values for the other attributes. For example, consider data about customers of a bank. Each record (customer) may be described using various attributes such as age, gender, city, education and steal-money?. Consider that steal-money? is an attribute that indicate whether a customer has stolen some money or not (yes or no). The goal of classification can be to guess whether a customer will steal money (yes or no) given the values of other attributes (the age, gender city and education) of a customer.
To do classification, the ID3 algorithm first creates a model using training data (records where the target attribute value is known). A model (a classifier) is a decision tree . After the model is created, it can be used to guess the missing value of the target attribute for a new record. For instance, using data about previous customers at the bank, it is possible to learn rules that can help to guess whether the new customers will steal money or not. There exists many algorithms for classication in the data mining literature.
This is a Java implementation of ID3. ID3 It is one of the most popular algorithm for learning decision trees. By searching on the web, you can find plenty of information on this algorithm. It is also described in several data mining books and artificial intelligence books.
A) How to train the ID3 model to make a prediction
How to run this example?
- This Example is not available in the graphical user interface of SPMF.
- If you are using the source code version of SPMF, launch the file "MainTestID3_single_prediction.java" in the package ca.pfv.SPMF.test
What is the input?
The input is a dataset that contains a set of records described according to some attributes . For instance, in this example, we use a dataset called tennisExtended.txt. This dataset is provided in the file "tennisExtended.txt." of the SPMF distribution. This dataset defines 7 attributes (outlook, temp, humid, wind, play, day and moon) and contains 19 instances (records).
| play | outlook | temp | humid | wind | day | moon |
| no | sunny | hot | high | weak | tuesday | full |
| no | sunny | hot | high | strong | tuesday | small |
| yes | overcast | hot | high | weak | tuesday | full |
| yes | rainy | mild | high | strong | tuesday | small |
| yes | rainy | cool | normal | weak | monday | full |
| no | rainy | cool | normal | strong | monday | small |
| yes | overcast | cool | normal | strong | monday | full |
| no | sunny | mild | high | weak | monday | small |
| yes | sunny | cool | normal | weak | monday | full |
| yes | rainy | mild | normal | weak | monday | small |
| yes | sunny | mild | normal | strong | friday | full |
| no | rainy | cool | normal | strong | friday | small |
| yes | overcast | cool | normal | strong | friday | full |
| no | sunny | mild | high | weak | friday | small |
| yes | sunny | cool | normal | weak | friday | full |
| yes | overcast | hot | high | weak | friday | small |
| yes | rainy | mild | high | strong | friday | full |
| yes | rainy | mild | normal | weak | friday | small |
| yes | sunny | mild | normal | strong | tuesday | full |
What is the model created by ID3?
The ID3 algorithm can be used to create a model that can be used to perform classification. The goal is to use that model to guess what is the missing value of a target attribute for a new record. For example, lets say that there is a new record where the value of the attribute "play" is unknown:
| ???? | rainy | mild | high | strong | monday | small |
The goal of classification is to build a model that will be able to predict the value ???? as either yes or no.
To build a model, ID3 takes as input:
- a training dataset that is used to build the model.
By applying the ID3 algorithm, a model is generated, which is a decision tree. It is a tree structure that looks like this (although not exactly like this for this example):
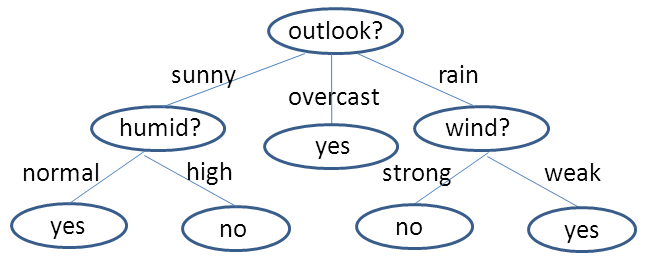
Using the trained model, the ID3 algorithm can make a prediction for the record:
| ???? | rainy | mild | high | strong | monday | small |
The prediction is: yes
Optional feature: saving a model to a file using serialization to load it again into memory later
Training is generally really fast. But if you want to save a trained model to a file and load it in memory later, it is possible. Saving the model done by uncommenting the following lines of code in the example:
classifier.saveTrainedClassifierToFile("classifier.ser"); // Save the model the a file
Loading a saved model is done using the following lines of code in the example:
classifier = Classifier.loadTrainedClassifierToFile("classifier.ser");
Optional feature: saving the model as a set of rules into a text file (for the purpose of analysis)
If you want to see the rules of the trained model, you may save them to a text file by uncommenting the following code in the example:
String rulesPath = "rulesPath.txt"
((RuleClassifier)classifier).writeRulesToFileSPMFFormatAsStrings(rulesPath,dataset);
where rulesPath.txt is the output file path and dataset is the training dataset.
Note that rules saves in this format cannot be loaded back in memory. If you want to save and load a model in memory, you should save rules using serialization (see above) instead.
Input format (default)
A few input file formats are supported by this algorithm. The first one is a text file such as the dataset "tennisExtended.txt." used in this example:
play outlook temp humid wind day moon
no sunny hot high weak tuesday full
no sunny hot high strong tuesday small
yes overcast hot high weak tuesday full
yes rainy mild high strong tuesday small
yes rainy cool normal weak monday full
no rainy cool normal strong monday small
yes overcast cool normal strong monday full
no sunny mild high weak monday small
yes sunny cool normal weak monday full
yes rainy mild normal weak monday small
yes sunny mild normal strong friday full
no rainy cool normal strong friday small
yes overcast cool normal strong friday full
no sunny mild high weak friday small
yes sunny cool normal weak friday full
yes overcast hot high weak friday small
yes rainy mild high strong friday full
yes rainy mild normal weak friday small
yes sunny mild normal strong tuesday full
The first line indicates the names of the attributes, each separated by a space. Then each of the following lines is a record where attribute values are separated by spaces. There are 19 records.
Alternative input format (ARFF)
It is also possible to use a dataset encoded using the ARFF format as an alternative to the default dataset format. The specification of the ARFF format can be found here. Most features of the ARFF format are supported except that all attribute values are treated as nominal values. This is due to the design of ID3, which is only defined for handling nominal values. If numerical values are in the data, they will be treated as nominal values (strings). To load a file using the ARFF format, the following lines of code can be used in the example:
String datasetPath = fileToPath("weather-train.arff");
ARFFDataset dataset = new ARFFDataset(datasetPath, targetClassName);
Using these lines, the dataset weather-train.aff will be used, which contains the following content:
@relation weather.tennis
@attribute outlook {sunny,overcast,rainy}
@attribute temperature {hot,mild,cool}
@attribute humidity {high,normal}
@attribute windy {strong,weak}
@attribute play {yes,no}
@data
sunny,hot,high,weak,no
sunny,hot,high,strong,no
overcast,hot,high,weak,yes
rainy,mild,high,weak,yes
rainy,cool,normal,weak,yes
rainy,cool,normal,strong,no
overcast,cool,normal,strong,yes
sunny,mild,high,weak,no
sunny,cool,normal,weak,yes
rainy,mild,normal,weak,yes
sunny,mild,normal,strong,yes
This dataset defines 5 attributes and 11 records (note that it is slightly different from the file tennisExtended.txt in the above example).
Alternative input format (CSV)
It is also possible to load a dataset encoded in the CSV format as an alternative to the default format and ARFF format. The CSV format is a file where values and attribute values are separated by commas. To load a file encoded according to the CSV format, the following lines of code can be used in the example:
String datasetPath = fileToPath("tennisExtendedCSV.txt");
CSVDataset dataset = new CSVDataset(datasetPath, targetClassName);
Using these lines, the dataset tennisExtendedCSV.txt can be read, which contains the following content:
play,outlook,temp,humid,wind,day,moon
no,sunny,hot,high,weak,tuesday,full
no,sunny,hot,high,strong,tuesday,small
yes,overcast,hot,high,weak,tuesday,full
yes,rainy,mild,high,strong,tuesday,small
yes,rainy,cool,normal,weak,monday,full
no,rainy,cool,normal,strong,monday,small
yes,overcast,cool,normal,strong,monday,full
no,sunny,mild,high,weak,monday,small
yes,sunny,cool,normal,weak,monday,full
yes,rainy,mild,normal,weak,monday,small
yes,sunny,mild,normal,strong,friday,full
no,rainy,cool,normal,strong,friday,small
yes,overcast,cool,normal,strong,friday,full
no,sunny,mild,high,weak,friday,small
yes,sunny,cool,normal,weak,friday,full
yes,overcast,hot,high,weak,friday,small
yes,rainy,mild,high,strong,friday,full
yes,rainy,mild,normal,weak,friday,small
yes,sunny,mild,normal,strong,tuesday,full
The first line indicates the names of the attributes, each separated by a comma. Then each of the following lines is a record where attribute values are separated by commas. There are 19 records.
B) How to run batch experiments to test the ID3 model for classification
In the SPMF library there is some code to automatically run experiments with ID3 on a dataset.
How to run this example?
- This Example is not available in the graphical user interface of SPMF.
- If you are using the source code version of SPMF, launch the file "MainTestID3_batch_holdout.java" in the package ca.pfv.SPMF.test
What is this example about?
In this example, the dataset tennisExtended.txt from the previous example is read into memory. It is then split into two parts : a training dataset (the first 50% of the records) and a testing dataset (the last 50% of the records).
The ID3 algorithm is then applied to build a model using the training dataset for the target attribute play.
Then, the model is applied to guess the values of the attribute play for all records in the test dataset. Statistics are then calculated in terms of various measures for evaluating a classifier and the results are presented in the console:
=== MODEL TRAINING RESULTS ===
#NAME: ID3
#RULECOUNT: 454 the number of rules in the model
#TIMEms: 15 the time for training the model (ms)
#MEMORYmb: 2.482 the memory used for training the model (MB)
==== CLASSIFICATION RESULTS ON TRAINING DATA =====
#NAME: ID3
#ACCURACY: 1 accuracy of the model on training data
#RECALL: 1 recall of the model on training data
#PRECISION: 1 precision of the model on training data
#KAPPA: NaN Kappa Score of the model on the training data
#FMICRO: 1 The F1 measure (micro) of the model on the training data
#FMACRO: 1 The F1 measure (macro of the model on the training data
#TIMEms: 0 the time for making predictions using the training data (ms)
#MEMORYmb: 1.9771 the memory usage for making predictions using the training data (MB)
#NOPREDICTION: 0.0 the percentage of records for which no prediction was made for the training data
==== CLASSIFICATION RESULTS ON TESTING DATA =====
#NAME: ID3
#ACCURACY: 0.7 accuracy of the model on the testing data
#RECALL: 0.625 recall of the model on the testing data
#PRECISION: 0.75 precision of the model on the testing data
#KAPPA: 0.375 Kappa Score of the model on the testing data
#FMICRO: 0.778 The F1 measure (micro) of the model on the testing data
#FMACRO: 0.6786 The F1 measure (macro) of the model on the testing data
#TIMEms: 0 the time for making predictions using the testing data (ms)
#MEMORYmb: 1.971 the memory usage for making predictions using the testing data (MB)
#NOPREDICTION: 0.0 the percentage of records for which no prediction was made for the testing data
These measures are commonly used for evaluating classification models (classifiers).
Optional feature: Using K-Fold Cross validation
The above example has shown how to split a dataset into two parts (training and testing) to evaluate a classifier. This approach called holdout is useful. However, a problem is that only part of the data is used for training (e.g. 50%) and only part of the data (e.g. 50%) is used for testing. To be able to use all the data for training and all the data for testing, there is an alternative way of testing a classifier, which is called k-fold cross-validation. To use k-fold cross-validation, the user must set a parameter k (a positive integer) indicating the number of folds (parts). For example, lets say that a dataset has 100 records and that k = 5. Then the dataset will be divided into 5 parts, each containing 20 records. Then, to evaluate the classifier, five experiments will be done:
- Records 1 to 20 are used for training, and the other 80 records are used for testing
- Records 21 to 40 are used for training, and the other 80 records are used for testing
- Records 41 to 60 are used for training, and the other 80 records are used for testing
- Records 61 to 80 are used for training, and the other 80 records are used for testing
- Records 81 to 100 are used for training, and the other 80 records are used for testing
Then, the average of the results are presented to the user for the five experiments.
To try k-fold cross-validation instead of holdout, you may run the example "MainTestID3_batch_kfold.java" in the package ca.pfv.spmf.test of the SPMF distribution